Scheduling Function Calls with Zero Allocation
| PV/UV:/ | PDF | #Channel #EscapeAnalysis #GUI #MainThread #Thread #Tracing #MemAllocAuthor(s): Changkun Ou
Permalink: https://golang.design/research/zero-alloc-call-sched
GUI programming in Go is a little bit tricky. The infamous issue
regarding interacting with legacy, GUI frameworks is that
most graphics related APIs must be called from the main thread.
The issue violates the concurrent nature of Go: A goroutine maybe
arbitrarily and randomly scheduled or rescheduled on different running
threads, i.e., the same piece of code will be called from different
threads over time, even without evolving the go keyword.
Background
In multithreaded programming, operating systems provide space, the so-called Thread Local Storage (TLS) for each thread of a process to store their private and local content. In the era where multithreaded programming and scheduling algorithms are not rich enough, the TLS feature was handy to avoid data race since this storage is purely local and guaranteed by the operating system.
For example, a graphics rendering backend such as OpenGL Context was designed to store each thread's rendering context on TLS; In macOS, the famous GUI framework Cocoa also requires rendering user interfaces on a specific thread, which is the so-called main thread.
The Main Thread
In Go, as we know that a goroutine will be scheduled to different threads due to its internal work-stealing scheduler 1 2.
With a work-stealing scheduler, goroutines are not promised to run on a specific thread forever. Instead, whenever a goroutine goes to sleep or entering a system call, or the Go runtime proactively interrupts the execution of that goroutine, it is likely to be rescheduled to a different thread. Therefore, if an (OpenGL) rendering context is stored on the old thread, switching to a new thread will cause the old context's loss. Because such an interruption can happen at any time and anywhere, it is impossible to check if the goroutine remains on the same thread when the execution resumes.
The original intention of designing such a scheduler is to eliminate the concept of system thread and multiplex it. In this way, users will not suffer from paying the cost of threads switch/sleep, whereas threads always in their full power mode that is continuously running tasks either from the user or the runtime.
Method runtime.LockOSThread and Package mainthread
If GUI applications must interact with the OS on the main thread,
how can we achieve the goal of running a specific thread permanently?
Luckily, there is a method called LockOSThread offered from the
runtime package, provides the same feature we want:
1// LockOSThread wires the calling goroutine to its current operating
2// system thread.
3// The calling goroutine will always execute in that thread,
4// and no other goroutine will execute in it,
5// until the calling goroutine has made as many calls to
6// UnlockOSThread as to LockOSThread.
7// If the calling goroutine exits without unlocking the thread,
8// the thread will be terminated.
9//
10// All init functions are run on the startup thread. Calling
11// LockOSThread from an init function will cause the main function
12// to be invoked on that thread.
13//
14// A goroutine should call LockOSThread before calling OS services or
15// non-Go library functions that depend on per-thread state.
16func LockOSThread()
As the LockOSThread document says: All init functions run on
the startup thread. Calling LockOSThread from an init function will
cause the primary function to be invoked on that thread.
If we think about that carefully, we will immediately realize this
allows us to identify, at least, the main thread. When we would like to
wrapping thread scheduling as a package mainthread, we can do
something like the following::
1package mainthread // import "x/mainthread"
2
3import "runtime"
4
5func init() {
6 runtime.LockOSThread()
7}
8
9// Init initializes the functionality of running arbitrary subsequent
10// functions be called on the main system thread.
11//
12// Init must be called in the main.main function.
13func Init(main func())
14
15// Call calls f on the main thread and blocks until f finishes.
16func Call(f func())
As a user of such a package, one can:
1package main
2
3func main() {
4 mainthread.Init(fn)
5}
6
7func fn() {
8 // ... do what ever we want to do in main ...
9}
10
11
12func gn() {
13 // Wherever gn is running, the call will be executed on
14 // the main thread.
15 mainthread.Call(func() {
16 // ... do whatever we want to run on the main thread ...
17 })
18}
Once we solved API design, the next question is: How can we implement
the Init and Call?
Well, it is not that difficult. Recall that we use Init method to
obtain the main thread's full control, then we should never give up
such power. Thus, creating another goroutine to run what we initially
want to run and use a channel to receive the calls that we would like
to schedule on the main thread becomes our only option:
1// funcQ is a global channel that responsible for receiving function
2// calls that needs to run on the main thread.
3var funcQ = make(chan func(), runtime.GOMAXPROCS(0))
4
5func Init(main func()) {
6 done := make(chan struct{})
7 go func() {
8 main()
9
10 // main function terminates, signal and terminate
11 // the main thread too.
12 done <- struct{}{}
13 }()
14
15 for {
16 select {
17 case f := <-funcQ:
18 f()
19 case <-done:
20 return
21 }
22 }
23}
Since we have the global funcQ, scheduling a function via that channel
becomes an easy work:
1// Call calls f on the main thread and blocks until f finishes.
2func Call(f func()) {
3 done := make(chan struct{})
4 funcQ <- func() {
5 f()
6 done <- struct{}{}
7 }
8 <-done
9}
Note that we use empty struct as our channel signal; if you are not familiar with empty struct and channels, you might want to read two great posts from Dave Cheney 6 7.
To use such a package, one can use mainthread.Call to schedule
a call to be executed on the main thread:
1package main
2
3import "x/mainthread"
4
5func main() {
6 mainthread.Init(fn)
7}
8
9func fn() {
10 done := make(chan struct{})
11 go gn(done)
12 <-done
13}
14
15func gn(done chan<- struct{}) {
16 mainthread.Call(func() {
17 println("call on the main thread.")
18 })
19 done <- struct{}{}
20}
Creating A Window with glfw using mainthread
Whenever we need to wrap a window package, such as initializing glfw 3:
1package app // import "x/app"
2
3import (
4 "x/mainthread"
5
6 "github.com/go-gl/glfw/v3.3/glfw"
7)
8
9// Init initializes an app environment.
10func Init() (err error) {
11 mainthread.Call(func() { err = glfw.Init() })
12 return
13}
14
15// Terminate terminates the entire application.
16func Terminate() {
17 mainthread.Call(glfw.Terminate)
18}
Furthermore, make sure critical calls like glfw.WaitEventsTimeout
inside the rendering loop always be executed from the main thread:
1package app // import "x/app"
2
3// Win is a window.
4type Win struct {
5 win *glfw.Window
6}
7
8// NewWindow constructs a new graphical window.
9func NewWindow() (*Win, error) {
10 var (
11 w = &Win{}
12 err error
13 )
14 mainthread.Call(func() {
15 w.win, err = glfw.CreateWindow(640, 480,
16 "golang.design/research", nil, nil)
17 if err != nil {
18 return
19 }
20 })
21 if err != nil {
22 return nil, err
23 }
24 w.win.MakeContextCurrent()
25 return w, nil
26}
27
28// Run runs the given window and blocks until it is destroied.
29func (w *Win) Run() {
30 for !w.win.ShouldClose() {
31 w.win.SwapBuffers()
32 mainthread.Call(func() {
33 // This function must be called from the main thread.
34 glfw.WaitEventsTimeout(1.0 / 30)
35 })
36 }
37 // This function must be called from the mainthread.
38 mainthread.Call(w.win.Destroy)
39}
As a user of the app package, we can get rid of the understanding
overhead regarding when and how should we call a function
on the main thread::
1package main
2
3import (
4 "x/app"
5 "x/mainthread"
6)
7
8func main() {
9 mainthread.Init(fn)
10}
11
12func fn() {
13 err := app.Init()
14 if err != nil {
15 panic(err)
16 }
17 defer app.Terminate()
18 w, err := app.NewWindow()
19 if err != nil {
20 panic(err)
21 }
22 w.Run()
23}
Now, we have an empty solid window and will never crash randomly 😄.
Cost Analysis and Optimization
After implementing a first iteration of the mainthread package,
we might directly wonder about this package's performance.
A question could be:
What is the latency when calling such a function if it is transmitted from a thread to the main thread?
Let us write a few benchmark tests that can measure the performance of such a call. The idea is straightforward, and we need a baseline to identify the initial cost of calling a function, then measure the completion time when we schedule the same function call on the main thread:
1var f = func() {}
2
3// Baseline: call f() directly.
4func BenchmarkDirectCall(b *testing.B) {
5 b.ReportAllocs()
6 b.ResetTimer()
7 for i := 0; i < b.N; i++ {
8 f()
9 }
10}
11
12// MainthreadCall: call f() on the mainthread.
13func BenchmarkMainThreadCall(b *testing.B) {
14 mainthread.Init(func() {
15 b.ReportAllocs()
16 b.ResetTimer()
17 for i := 0; i < b.N; i++ {
18 mainthread.Call(f)
19 }
20 })
21}
Be careful with micro-benchmarks here: Referring to our previous
discussion about the time measurement of benchmarks 4,
let us use the benchmarking tool 5. The bench is a tool
for executing Go benchmarks reliably, and it automatically locks
the machine's performance and executes benchmarks 10x by default
to eliminate system measurement error:
$ bench
goos: darwin
goarch: arm64
pkg: x/mainthread-naive
...
name time/op
DirectCall-8 0.95ns ±1%
MainThreadCall-8 448ns ±0%
name alloc/op
DirectCall-8 0.00B
MainThreadCall-8 120B ±0%
name allocs/op
DirectCall-8 0.00
MainThreadCall-8 2.00 ±0%
The benchmark result indicates that calling an empty function directly
in Go will 1ns whereas schedule the same empty function to
the main thread will spend 448ns. Thus the cost is 447ns.
Moreover, when we talk about cost, we care about the cost of CPU and
memory consumption. According to the second report regarding allocs/op,
the result shows scheduling an empty function to the mainthread
will cost 120B allocation.
Allocation of 120B per operation might not be a big deal from
our first impression. However, if we consider the actual use case of
this package, i.e., managing GUI rendering calls, either CPU or
memory allocation can be propagated to a considerable cost over time.
If we are dealing with rendering, especially graphical rendering,
the new rate is typically a minimum of 25fps, ideally 30fps or even higher.
That means, for every 5 minutes, without considering mouse button, movements, and keystrokes, a GUI application will allocate at least:
$$ 5 \times 60\times 30 \times 120 \text{byte} = 1.08 \text{MiB} $$
A direct impact from an excessive allocation behavior is the runtime garbage collector and the scavenger. With a higher allocation rate, the garbage collector is triggered more often, and the scavenger releases memory to the OS more often. Because more works are produced for the GC, the GC will also consume more CPU from the system. It is good enough to say the entire application is a vicious circle.
The following is trace information of that above application runs in 6 minutes, and the total heap allocation is 1.41 MiB (2113536-630784 byte), pretty close to what we predicted before.
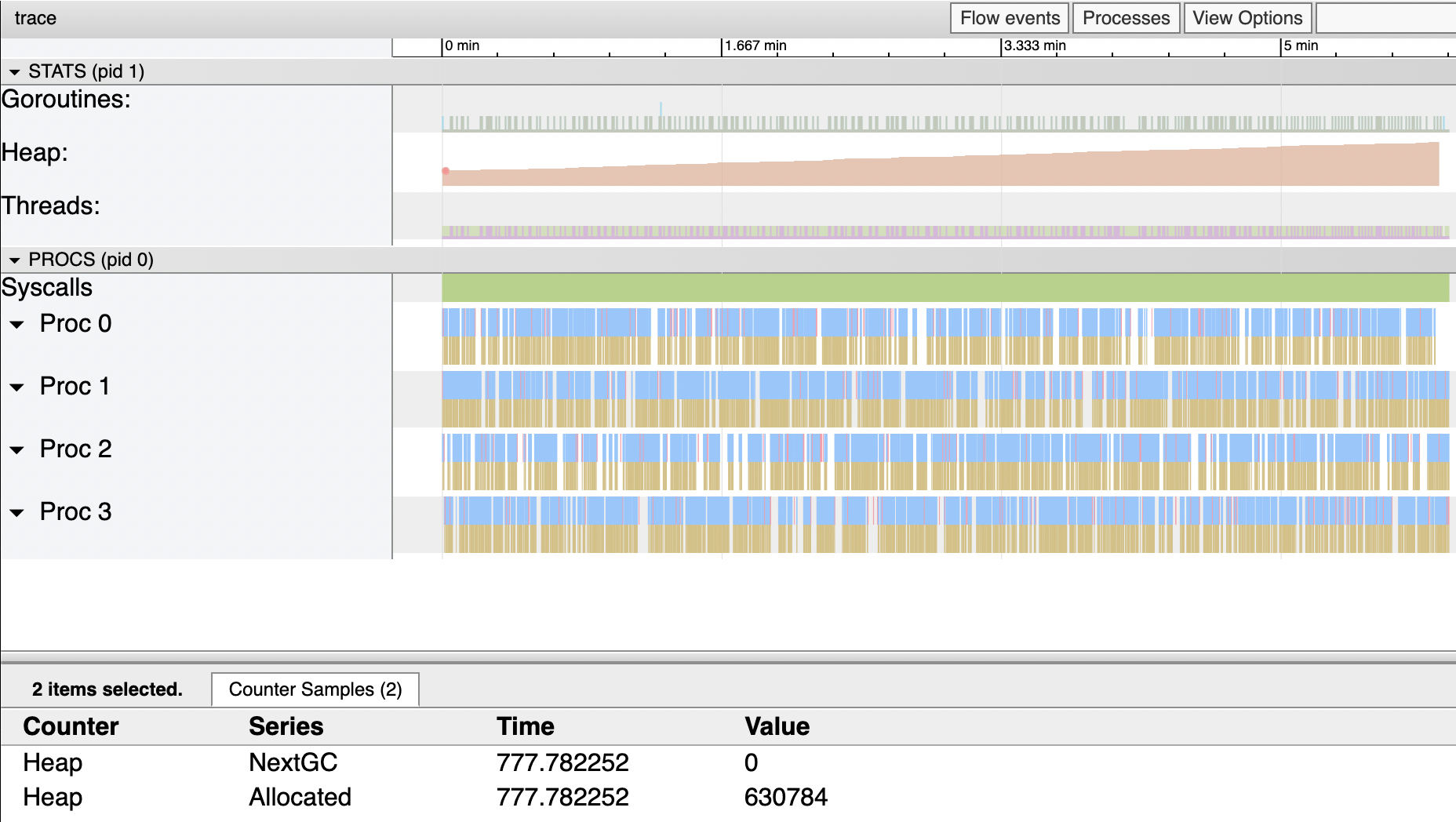
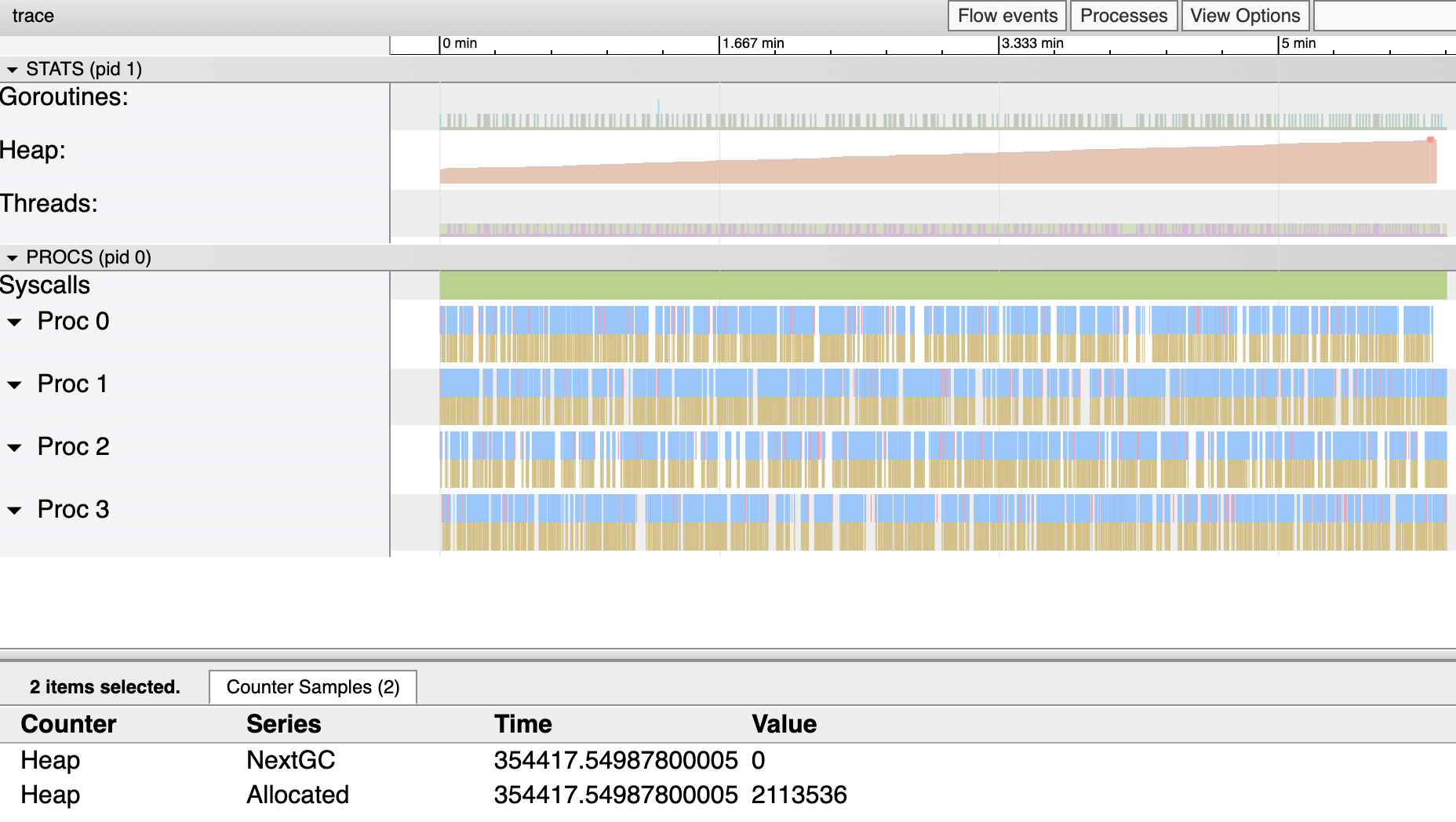
Where does the allocation occur? How can we deal with these issues? How to optimize the existing naive implementation? Let us find out in the next section.
Optimal Threading Control
The first optimization comes to the attempt to avoid allocating channels.
In our Call implementation, we allocate a signal channel for
every function that we need to call from the main thread:
1// Call calls f on the main thread and blocks until f finishes.
2func Call(f func()) {
3 done := make(chan struct{}) // allocation!
4 funcQ <- func() {
5 f()
6 done <- struct{}{}
7 }
8 <-done
9}
Thus, whenever we call the Call method, we will have to allocate
at least 96 bytes for a channel due to the Go compiler will uses
runtime.hchan as the struct that represents the channel under the hood:
1// in src/runtime/chan.go
2
3// the hchan struct needs 96 bytes.
4type hchan struct {
5 qcount uint
6 dataqsiz uint
7 buf unsafe.Pointer
8 elemsize uint16
9 closed uint32
10 elemtype *_type
11 sendx uint
12 recvx uint
13 recvq waitq
14 sendq waitq
15 lock mutex
16}
A well-known trick to avoid repetitive allocation is to use
the sync.Pool. One can:
1var donePool = sync.Pool{New: func() interface{} {
2 return make(chan struct{})
3}}
4
5func Call(f func()) {
6 // reuse signal channel via sync.Pool!
7 done := donePool.Get().(chan struct{})
8 defer donePool.Put(done)
9
10 funcQ <- func() {
11 f()
12 done <- struct{}{}
13 }
14 <-done
15}
With that simple optimization, a benchmarked result indicates an 80% reduction of memory usage:
1name old time/op new time/op delta
2DirectCall-8 0.95ns ±1% 0.95ns ±1% ~ (p=0.631 n=10+10)
3MainThreadCall-8 448ns ±0% 440ns ±0% -1.83% (p=0.000 n=9+9)
4
5name old alloc/op new alloc/op delta
6DirectCall-8 0.00B 0.00B ~ (all equal)
7MainThreadCall-8 120B ±0% 24B ±0% -80.00% (p=0.000 n=10+10)
8
9name old allocs/op new allocs/op delta
10DirectCall-8 0.00 0.00 ~ (all equal)
11MainThreadCall-8 2.00 ±0% 1.00 ±0% -50.00% (p=0.000 n=10+10)
Can we do it even better? The answer is yes. One can notice that there is still a 24B of allocation per operation. However, to identify it becomes somewhat tricky.
In Go, variables can be allocated from heap if:
- Using
makeandnewkeywords explicitly, or - Escape from the stack
The second case is a little bit advance from the regular use of Go. To be short, escape from the execution stack to the heap is decided from compile time. The Go's compiler will decide when a variable should be allocated on the heap. Deciding to allocate variables either on the stack or the heap is called escape analysis.
The great thing about Go is that this information is trackable and
can be enabled directly from the Go toolchain.
One can use -gcflags="-m" to activate the escape analysis and
see the result from the compile-time:
1$ go build -gcflags="-m"
2./mainthread.go:52:11: can inline Call.func1
3./mainthread.go:48:11: leaking param: f
4./mainthread.go:52:11: func literal escapes to heap
The compiler shows us that the sending function is leaking,
and the wrapper function that sends via our funcQ is causing
the function literal escaping to the heap.
The function literal escapes to the heap because a function literal
is considered a pointer, and sending a pointer via channel will always
cause an escape by design.
To avoid the escaping function literal, instead of using a function wrapper, we can send a struct:
1type funcdata struct {
2 fn func()
3 done chan struct{}
4}
5
6func Call(f func()) {
7 done := donePool.Get().(chan struct{})
8 defer donePool.Put(done)
9
10 funcQ <- funcdata{fn: f, done: done} // wrap the information
11 <-done
12}
and when we receive the funcdata:
1func Init(main func()) {
2 ...
3
4 for {
5 select {
6 case fdata := <-funcQ:
7 fdata.fn()
8 fdata.done <- struct{}{}
9 case <-done:
10 return
11 }
12 }
13}
After such an optimization, a re-benchmarked result indicates that we hint the zero-allocation goal:
1name old time/op new time/op delta
2DirectCall-8 0.95ns ±1% 0.95ns ±1% ~ (p=0.896 n=10+10)
3MainThreadCall-8 448ns ±0% 366ns ±1% -18.17% (p=0.000 n=9+9)
4
5name old alloc/op new alloc/op delta
6DirectCall-8 0.00B 0.00B ~ (all equal)
7MainThreadCall-8 120B ±0% 0B -100.00% (p=0.000 n=10+10)
8
9name old allocs/op new allocs/op delta
10DirectCall-8 0.00 0.00 ~ (all equal)
11MainThreadCall-8 2.00 ±0% 0.00 -100.00% (p=0.000 n=10+10)
Hooray! 🎉
Update (2026): A clarification on the latency numbers above (e.g.
366ns,447ns). These benchmarks callmainthread.Initfrom inside the benchmark function, so undergo testthe event loop runs on the ordinary, unlocked goroutine thattestingspawned for the benchmark — not on goroutine 1, the thread pinned byruntime.LockOSThreadininit. In other words, they measure the cost of handing a call to the scheduler goroutine, not to the actual main thread. Dispatching to the real locked main thread is considerably more expensive and platform dependent: re-measuring the very sameopt2code with the loop running on goroutine 1 (via aTestMainthat callsInit) yields about9µs/op on an Apple M2 — roughly 25× the reported366ns— and the figure is noisy, because it is dominated by the OS cost of waking a specific locked thread.This does not affect the article's thesis. The allocation results are unchanged: scheduling is zero-allocation on either path (
0 B/op,0 allocs/op), and that remains the contribution of this work. What changes is only the interpretation of the absolute latency — the number to keep in mind for real main-thread scheduling is this microsecond-scale wakeup cost, which is inherent to the OS thread and cannot be optimized away in userland.
Verification and Discussion
Before we conclude this research, let us do a final verification on the real-world example that we had before: the GUI application.
While a re-evaluation, we can see from the trace file that the entire application is still allocating memory and the heap is still increasing:
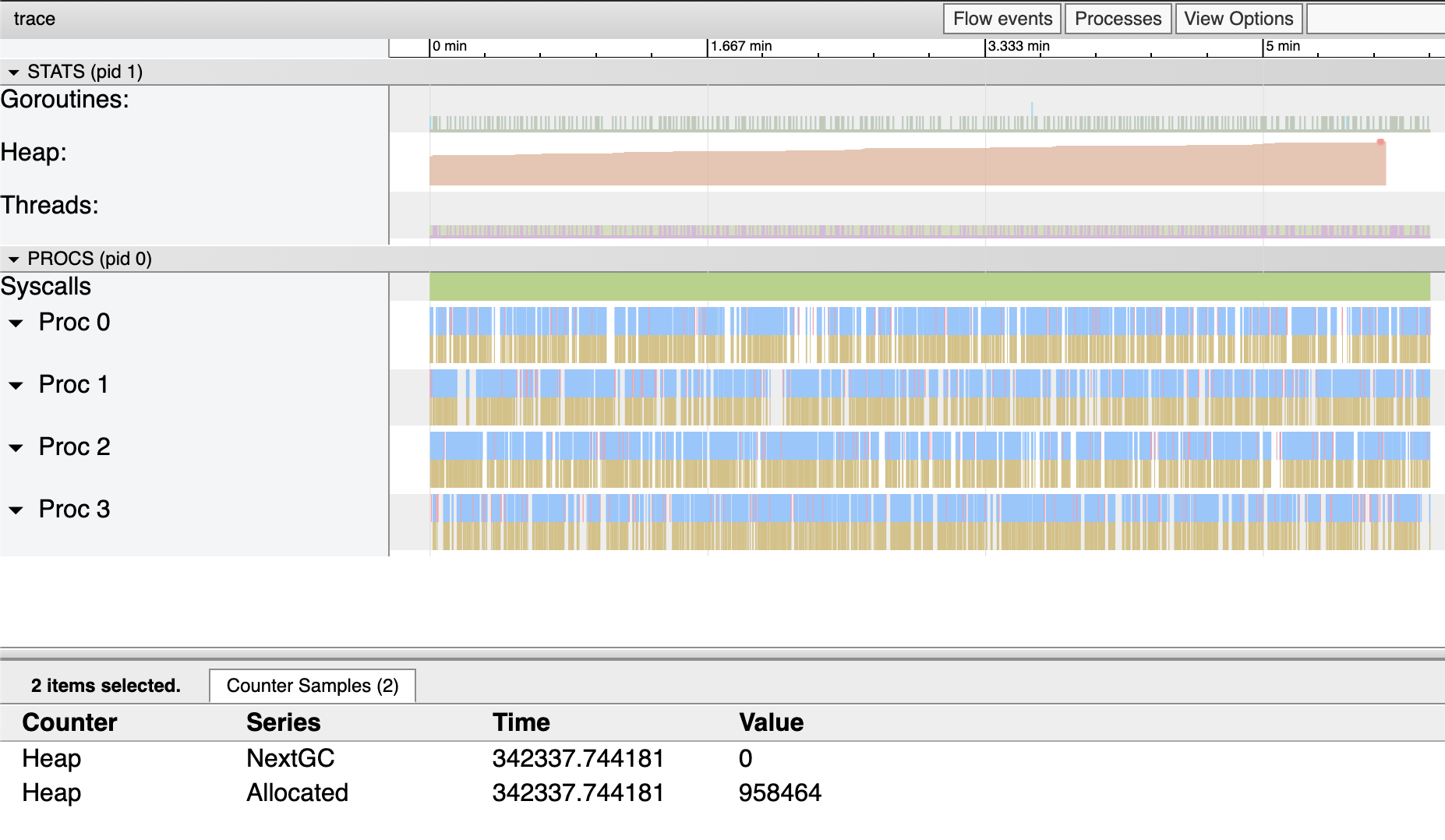
Notably, the total allocated bytes during the application life cycle (6 minutes) only allocates:
$$ 958464 - 622592 = 0.32 \text{MiB} $$
Compared to the previous 1.41 MiB allocation, we optimized 1.08 MiB of memory, which we precisely predicted before.
We might still wonder if scheduling is not allocating memory anymore,
who is still allocating the memory? To find out, we need a little bit of
help from the runtime package. The compiler translates the allocation
operation to a runtime function runtime.newobject. One can add 3
more lines and prints, which is exactly calling this function
using runtime.FuncForPC:
1// src/runtime/malloc.go
2func newobject(typ *_type) unsafe.Pointer {
3 f := FuncForPC(getcallerpc()) // add this
4 l, ll := f.FileLine(getcallerpc()) // add this
5 println(typ.size, f.Name(), l, ll) // add this
6 return mallocgc(typ.size, typ, true)
7}
In the above, the getcallerpc is a runtime private helper.
If we execute the application again, we will see printed information
similar to below:
88 runtime.acquireSudog /Users/changkun/dev/godev/go-github/src/runtime/proc.go 375
88 runtime.acquireSudog /Users/changkun/dev/godev/go-github/src/runtime/proc.go 375
88 runtime.acquireSudog /Users/changkun/dev/godev/go-github/src/runtime/proc.go 375
...
It demonstrates how and why the allocation still happens:
1// ch <- elem
2func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
3 ...
4 gp := getg()
5 mysg := acquireSudog()
6 ...
7}
8
9//go:nosplit
10func acquireSudog() *sudog {
11 mp := acquirem()
12 pp := mp.p.ptr()
13 if len(pp.sudogcache) == 0 {
14 lock(&sched.sudoglock)
15 for len(pp.sudogcache) < cap(pp.sudogcache)/2 && sched.sudogcache != nil {
16 s := sched.sudogcache
17 sched.sudogcache = s.next
18 s.next = nil
19 pp.sudogcache = append(pp.sudogcache, s)
20 }
21 unlock(&sched.sudoglock)
22 if len(pp.sudogcache) == 0 {
23 pp.sudogcache = append(pp.sudogcache, new(sudog)) // !here
24 }
25 }
26 ...
27}
Unfortunately, this is entirely outside the control of the userland. We are not able to optimize here anymore. Nevertheless, we have reached our goal for today, and this is the best of what we can do so far.
One more thing, if we take a closer look into how much the heap grows for one step, we will get some calculation like this: 671744-663552=8192 The result is, in fact, the minimum allocation size of the runtime allocator, which allocates a page. Since the discussion of such a topic has deviated from this research's goal, we leave that as a future outlook.
Conclusion
In this research, we covered the following topics:
- The Go runtime scheduler
- The Go runtime memory allocator
- The Go runtime garbage collector
- Scheduling on a specific thread, especially the main thread
- Reliable benchmarking and allocations tracing techniques
- Escape analysis
- The channel implementation in Go
There are several points we can summarize:
- A channel allocates 96 bytes of memory
- A function literal allocate 24 bytes of memory
- Escape analysis can help us identify unexpected allocations, and function literal is considered as a pointer that always escapes to the heap
- Sending information via a channel can cause allocation intrinsically from the runtime.
- Go runtime grows the heap 8K on each step as page allocation
We also encapsulated all the abstractions from this research and published two packages: mainthread9 and thread10. These packages allow us to schedule any function calls either on the main thread or a specific thread. Furthermore, We also submitted a pull request to the Fyne project11, which could reduce a considerable amount of memory allocations from the existing real-world GUI applications.
Have fun!
References
-
Robert D. Blumofe and Charles E. Leiserson. 1999. “Scheduling multithreaded computations by work stealing.” J. ACM 46, 5 (September 1999), 720-748. https://dl.acm.org/citation.cfm?id=324234↩
-
Dmitry Vyukov. “Scalable Go Scheduler Design Doc.” May 2, 2012. https://golang.org/s/go11sched↩
-
The glfw Library. https://www.glfw.org/↩
-
Changkun Ou. “Eliminating A Source of Measurement Errors in Benchmarks .” 30.09.2020. https://golang.design/research/bench-time/↩
-
Changkun Ou. “bench: Reliable performance measurement for Go programs. All in one design.” https://golang.design/s/bench↩
-
Dave Cheney. “The empty struct.” March 25, 2014. https://dave.cheney.net/2014/03/25/the-empty-struct↩
-
Dave Cheney. “Curious Channels.” April 30, 2013. https://dave.cheney.net/2013/04/30/curious-channels↩
-
Dave Cheney. “A few bytes here, a few there, pretty soon you're talking real memory.” Jan 05, 2021. https://dave.cheney.net/2021/01/05/a-few-bytes-here-a-few-there-pretty-soon-youre-talking-real-memory↩
-
Changkun Ou. “Package golang.design/x/mainthread.” https://golang.design/s/mainthread↩
-
Changkun Ou. “Package golang.design/x/thread.” https://golang.design/s/thread↩
-
Changkun Ou. “Optimize the cost of calling on the main/draw threads.” Jan 20, 2021 https://github.com/fyne-io/fyne/pull/1837↩