Pointers Might Not be Ideal as Arguments
| PV/UV:/ | PDF | #Performance #Parameter #PointerAuthor(s): Changkun Ou
Permalink: https://golang.design/research/pointer-params
We are aware that using pointers for passing parameters can avoid data copy, which will benefit the performance. Nevertheless, there are always some edge cases we might need concern.
Introduction
Let's take this as an example:
1// vec.go
2type vec struct {
3 x, y, z, w float64
4}
5
6func (v vec) addv(u vec) vec {
7 return vec{v.x + u.x, v.y + u.y, v.z + u.z, v.w + u.w}
8}
9
10func (v *vec) addp(u *vec) *vec {
11 v.x, v.y, v.z, v.w = v.x+u.x, v.y+u.y, v.z+u.z, v.w+u.w
12 return v
13}
Which vector addition runs faster?
Intuitively, we might consider that vec.addp is faster than vec.addv
because its parameter u uses pointer form. There should be no copies
of the data, whereas vec.addv involves data copy both when passing and
returning.
However, if we do a micro-benchmark:
1func BenchmarkVec(b *testing.B) {
2 b.Run("addv", func(b *testing.B) {
3 v1 := vec{1, 2, 3, 4}
4 v2 := vec{4, 5, 6, 7}
5 b.ReportAllocs()
6 b.ResetTimer()
7 for i := 0; i < b.N; i++ {
8 if i%2 == 0 {
9 v1 = v1.addv(v2)
10 } else {
11 v2 = v2.addv(v1)
12 }
13 }
14 })
15 b.Run("addp", func(b *testing.B) {
16 v1 := &vec{1, 2, 3, 4}
17 v2 := &vec{4, 5, 6, 7}
18 b.ReportAllocs()
19 b.ResetTimer()
20 for i := 0; i < b.N; i++ {
21 if i%2 == 0 {
22 v1 = v1.addp(v2)
23 } else {
24 v2 = v2.addp(v1)
25 }
26 }
27 })
28}
And run as follows:
1$ perflock -governor 80% go test -v -run=none -bench=. -count=10 | \
2 tee new.txt
3$ benchstat new.txt
The benchstat will give you the following result:
name time/op
Vec/addv-16 0.25ns ± 2%
Vec/addp-16 2.20ns ± 0%
name alloc/op
Vec/addv-16 0.00B
Vec/addp-16 0.00B
name allocs/op
Vec/addv-16 0.00
Vec/addp-16 0.00
How is this happening?
Inlining Optimization
This is all because of compiler optimization, and mostly because of inlining.
If we disable inline1 2 from the addv and addp:
1//go:noinline
2func (v vec) addv(u vec) vec {
3 return vec{v.x + u.x, v.y + u.y, v.z + u.z, v.w + u.w}
4}
5
6//go:noinline
7func (v *vec) addp(u *vec) *vec {
8 v.x, v.y, v.z, v.w = v.x+u.x, v.y+u.y, v.z+u.z, v.w+u.w
9 return v
10}
Then run the benchmark and compare the perf with the previous one:
1$ perflock -governor 80% go test -v -run=none -bench=. -count=10 | \
2 tee old.txt
3$ benchstat old.txt new.txt
4name old time/op new time/op delta
5Vec/addv-16 4.99ns ± 1% 0.25ns ± 2% -95.05% (p=0.000 n=9+10)
6Vec/addp-16 3.35ns ± 1% 2.20ns ± 0% -34.37% (p=0.000 n=10+8)
The inline optimization transforms the vec.addv:
1v1 := vec{1, 2, 3, 4}
2v2 := vec{4, 5, 6, 7}
3v1 = v1.addv(v2)
to a direct assign statement:
1v1 := vec{1, 2, 3, 4}
2v2 := vec{4, 5, 6, 7}
3v1 = vec{1+4, 2+5, 3+6, 4+7}
And for the vec.addp's case:
1v1 := &vec{1, 2, 3, 4}
2v2 := &vec{4, 5, 6, 7}
3v1 = v1.addp(v2)
to a direct manipulation:
1v1 := vec{1, 2, 3, 4}
2v2 := vec{4, 5, 6, 7}
3v1.x, v1.y, v1.z, v1.w = v1.x+v2.x, v1.y+v2.y, v1.z+v2.z, v1.w+v2.w
Addressing Modes
If we check the compiled assembly, the reason reveals quickly:
1$ mkdir asm && go tool compile -S vec.go > asm/vec.s
The dumped assumbly code is as follows:
"".vec.addv STEXT nosplit size=89 args=0x60 locals=0x0 funcid=0x0
0x0000 00000 (vec.go:7) TEXT "".vec.addv(SB), NOSPLIT|ABIInternal, $0-96
0x0000 00000 (vec.go:7) FUNCDATA $0, gclocals·...(SB)
0x0000 00000 (vec.go:7) FUNCDATA $1, gclocals·...(SB)
0x0000 00000 (vec.go:8) MOVSD "".u+40(SP), X0
0x0006 00006 (vec.go:8) MOVSD "".v+8(SP), X1
0x000c 00012 (vec.go:8) ADDSD X1, X0
0x0010 00016 (vec.go:8) MOVSD X0, "".~r1+72(SP)
0x0016 00022 (vec.go:8) MOVSD "".u+48(SP), X0
0x001c 00028 (vec.go:8) MOVSD "".v+16(SP), X1
0x0022 00034 (vec.go:8) ADDSD X1, X0
0x0026 00038 (vec.go:8) MOVSD X0, "".~r1+80(SP)
0x002c 00044 (vec.go:8) MOVSD "".u+56(SP), X0
0x0032 00050 (vec.go:8) MOVSD "".v+24(SP), X1
0x0038 00056 (vec.go:8) ADDSD X1, X0
0x003c 00060 (vec.go:8) MOVSD X0, "".~r1+88(SP)
0x0042 00066 (vec.go:8) MOVSD "".u+64(SP), X0
0x0048 00072 (vec.go:8) MOVSD "".v+32(SP), X1
0x004e 00078 (vec.go:8) ADDSD X1, X0
0x0052 00082 (vec.go:8) MOVSD X0, "".~r1+96(SP)
0x0058 00088 (vec.go:8) RET
"".(*vec).addp STEXT nosplit size=73 args=0x18 locals=0x0 funcid=0x0
0x0000 00000 (vec.go:11) TEXT "".(*vec).addp(SB), NOSPLIT|ABIInternal, $0-24
0x0000 00000 (vec.go:11) FUNCDATA $0, gclocals·...(SB)
0x0000 00000 (vec.go:11) FUNCDATA $1, gclocals·...(SB)
0x0000 00000 (vec.go:12) MOVQ "".u+16(SP), AX
0x0005 00005 (vec.go:12) MOVSD (AX), X0
0x0009 00009 (vec.go:12) MOVQ "".v+8(SP), CX
0x000e 00014 (vec.go:12) ADDSD (CX), X0
0x0012 00018 (vec.go:12) MOVSD 8(AX), X1
0x0017 00023 (vec.go:12) ADDSD 8(CX), X1
0x001c 00028 (vec.go:12) MOVSD 16(CX), X2
0x0021 00033 (vec.go:12) ADDSD 16(AX), X2
0x0026 00038 (vec.go:12) MOVSD 24(AX), X3
0x002b 00043 (vec.go:12) ADDSD 24(CX), X3
0x0030 00048 (vec.go:12) MOVSD X0, (CX)
0x0034 00052 (vec.go:12) MOVSD X1, 8(CX)
0x0039 00057 (vec.go:12) MOVSD X2, 16(CX)
0x003e 00062 (vec.go:12) MOVSD X3, 24(CX)
0x0043 00067 (vec.go:13) MOVQ CX, "".~r1+24(SP)
0x0048 00072 (vec.go:13) RET
The addv implementation uses values from the previous stack frame and
writes the result directly to the return; whereas addp needs MOVQ3 4 5 that
copies the parameter to different registers (e.g., copy pointers to AX and CX),
then write back when returning. Therefore, with inline disabled, the reason that addv is slower than addp is caused by different memory access pattern.
Conclusion
Can pass by value always faster than pass by pointer? We could do a further test. But this time, we need use a generator to generate all possible cases. Here is how we could do it:
1// gen.go
2
3// +build ignore
4
5package main
6
7import (
8 "bytes"
9 "fmt"
10 "go/format"
11 "io/ioutil"
12 "strings"
13 "text/template"
14)
15
16var (
17 head = `// Code generated by go run gen.go; DO NOT EDIT.
18package fields_test
19
20import "testing"
21`
22 structTmpl = template.Must(template.New("ss").Parse(`
23type {{.Name}} struct {
24 {{.Properties}}
25}
26
27func (s {{.Name}}) addv(ss {{.Name}}) {{.Name}} {
28 return {{.Name}}{
29 {{.Addv}}
30 }
31}
32
33func (s *{{.Name}}) addp(ss *{{.Name}}) *{{.Name}} {
34 {{.Addp}}
35 return s
36}
37`))
38 benchHead = `func BenchmarkVec(b *testing.B) {`
39 benchTail = `}`
40 benchBody = template.Must(template.New("bench").Parse(`
41 b.Run("addv-{{.Name}}", func(b *testing.B) {
42 {{.InitV}}
43 b.ResetTimer()
44 for i := 0; i < b.N; i++ {
45 if i%2 == 0 {
46 v1 = v1.addv(v2)
47 } else {
48 v2 = v2.addv(v1)
49 }
50 }
51 })
52 b.Run("addp-{{.Name}}", func(b *testing.B) {
53 {{.InitP}}
54 b.ResetTimer()
55 for i := 0; i < b.N; i++ {
56 if i%2 == 0 {
57 v1 = v1.addp(v2)
58 } else {
59 v2 = v2.addp(v1)
60 }
61 }
62 })
63`))
64)
65
66type structFields struct {
67 Name string
68 Properties string
69 Addv string
70 Addp string
71}
72type benchFields struct {
73 Name string
74 InitV string
75 InitP string
76}
77
78func main() {
79 w := new(bytes.Buffer)
80 w.WriteString(head)
81
82 N := 10
83
84 for i := 0; i < N; i++ {
85 var (
86 ps = []string{}
87 adv = []string{}
88 adpl = []string{}
89 adpr = []string{}
90 )
91 for j := 0; j <= i; j++ {
92 ps = append(ps, fmt.Sprintf("x%d\tfloat64", j))
93 adv = append(adv, fmt.Sprintf("s.x%d + ss.x%d,", j, j))
94 adpl = append(adpl, fmt.Sprintf("s.x%d", j))
95 adpr = append(adpr, fmt.Sprintf("s.x%d + ss.x%d", j, j))
96 }
97 err := structTmpl.Execute(w, structFields{
98 Name: fmt.Sprintf("s%d", i),
99 Properties: strings.Join(ps, "\n"),
100 Addv: strings.Join(adv, "\n"),
101 Addp: strings.Join(adpl, ",") + " = " +
102 strings.Join(adpr, ","),
103 })
104 if err != nil {
105 panic(err)
106 }
107 }
108
109 w.WriteString(benchHead)
110 for i := 0; i < N; i++ {
111 nums1, nums2 := []string{}, []string{}
112 for j := 0; j <= i; j++ {
113 nums1 = append(nums1, fmt.Sprintf("%d", j))
114 nums2 = append(nums2, fmt.Sprintf("%d", j+i))
115 }
116 numstr1 := strings.Join(nums1, ", ")
117 numstr2 := strings.Join(nums2, ", ")
118
119 err := benchBody.Execute(w, benchFields{
120 Name: fmt.Sprintf("s%d", i),
121 InitV: fmt.Sprintf(`v1 := s%d{%s}
122v2 := s%d{%s}`, i, numstr1, i, numstr2),
123 InitP: fmt.Sprintf(`v1 := &s%d{%s}
124 v2 := &s%d{%s}`, i, numstr1, i, numstr2),
125 })
126 if err != nil {
127 panic(err)
128 }
129 }
130 w.WriteString(benchTail)
131
132 out, err := format.Source(w.Bytes())
133 if err != nil {
134 panic(err)
135 }
136 err = ioutil.WriteFile("impl_test.go", out, 0660)
137 if err != nil {
138 panic(err)
139 }
140}
If we generate our test code and perform the same benchmark procedure again:
1$ go generate
2$ perflock -governor 80% go test -v -run=none -bench=. -count=10 | \
3 tee inline.txt
4$ benchstat inline.txt
5name time/op
6Vec/addv-s0-16 0.25ns ± 0%
7Vec/addp-s0-16 2.20ns ± 0%
8Vec/addv-s1-16 0.49ns ± 1%
9Vec/addp-s1-16 2.20ns ± 0%
10Vec/addv-s2-16 0.25ns ± 1%
11Vec/addp-s2-16 2.20ns ± 0%
12Vec/addv-s3-16 0.49ns ± 2%
13Vec/addp-s3-16 2.21ns ± 1%
14Vec/addv-s4-16 8.29ns ± 0%
15Vec/addp-s4-16 2.37ns ± 1%
16Vec/addv-s5-16 9.06ns ± 1%
17Vec/addp-s5-16 2.74ns ± 1%
18Vec/addv-s6-16 9.9ns ± 0%
19Vec/addp-s6-16 3.17ns ± 0%
20Vec/addv-s7-16 10.9ns ± 1%
21Vec/addp-s7-16 3.27ns ± 1%
22Vec/addv-s8-16 11.4ns ± 0%
23Vec/addp-s8-16 3.29ns ± 0%
24Vec/addv-s9-16 13.4ns ± 1%
25Vec/addp-s9-16 3.37ns ± 0%
We could even further try a version that disables inline:
1structTmpl = template.Must(template.New("ss").Parse(`
2type {{.Name}} struct {
3 {{.Properties}}
4}
5+//go:noinline
6func (s {{.Name}}) addv(ss {{.Name}}) {{.Name}} {
7 return {{.Name}}{
8 {{.Addv}}
9 }
10}
11+//go:noinline
12func (s *{{.Name}}) addp(ss *{{.Name}}) *{{.Name}} {
13 {{.Addp}}
14 return s
15}
16`))
Eventually, we will endup with the following results:
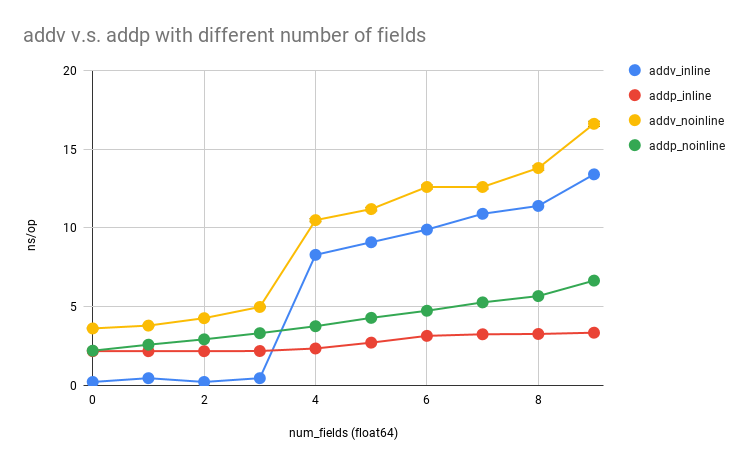
TLDR: The above figure basically demonstrates when should you pass-by-value or pass-by-pointer. If you are certain that your code won't produce any escape variables, and the size of your argument is smaller than 4*8 = 32 bytes, then you should go for pass-by-value; otherwise, you should keep using pointers.
References
-
Dave Cheney. Mid-stack inlining in Go. May 2, 2020. https://dave.cheney.net/2020/05/02/mid-stack-inlining-in-go↩
-
Dave Cheney. Inlining optimisations in Go. April 25, 2020. https://dave.cheney.net/2020/04/25/inlining-optimisations-in-go↩
-
MOVSD. Move or Merge Scalar Double-Precision Floating-Point Value. Last access: 2020-10-27. https://www.felixcloutier.com/x86/movsd↩
-
ADDSD. Add Scalar Double-Precision Floating-Point Values. Last access: 2020-10-27. https://www.felixcloutier.com/x86/addsd↩
-
MOVEQ. Move Quadword. Last access: 2020-10-27. https://www.felixcloutier.com/x86/movq↩